OCR Technology Types
Traditional OCR converts images to text but requires templates. Intelligent Document Processing (IDP) uses AI to understand document structure. Computer Vision identifies document regions and field types. Natural Language Processing extracts meaning from unstructured text. Modern systems combine all three approaches.
Document Classification
Automatic classification identifies document type without manual sorting. Common financial documents include: invoices, POs, receipts, statements, checks, contracts. Classification accuracy should exceed 99% for production use. Misclassified documents route to exception queues for manual handling.
Data Extraction Challenges
Poor scan quality, skewed images, and noise reduce accuracy. Multi-page documents require page ordering and relationship understanding. Tables and line items need special handling for structure preservation. Handwriting varies significantly and requires specialized models. Stamped or overlaid text can interfere with extraction.
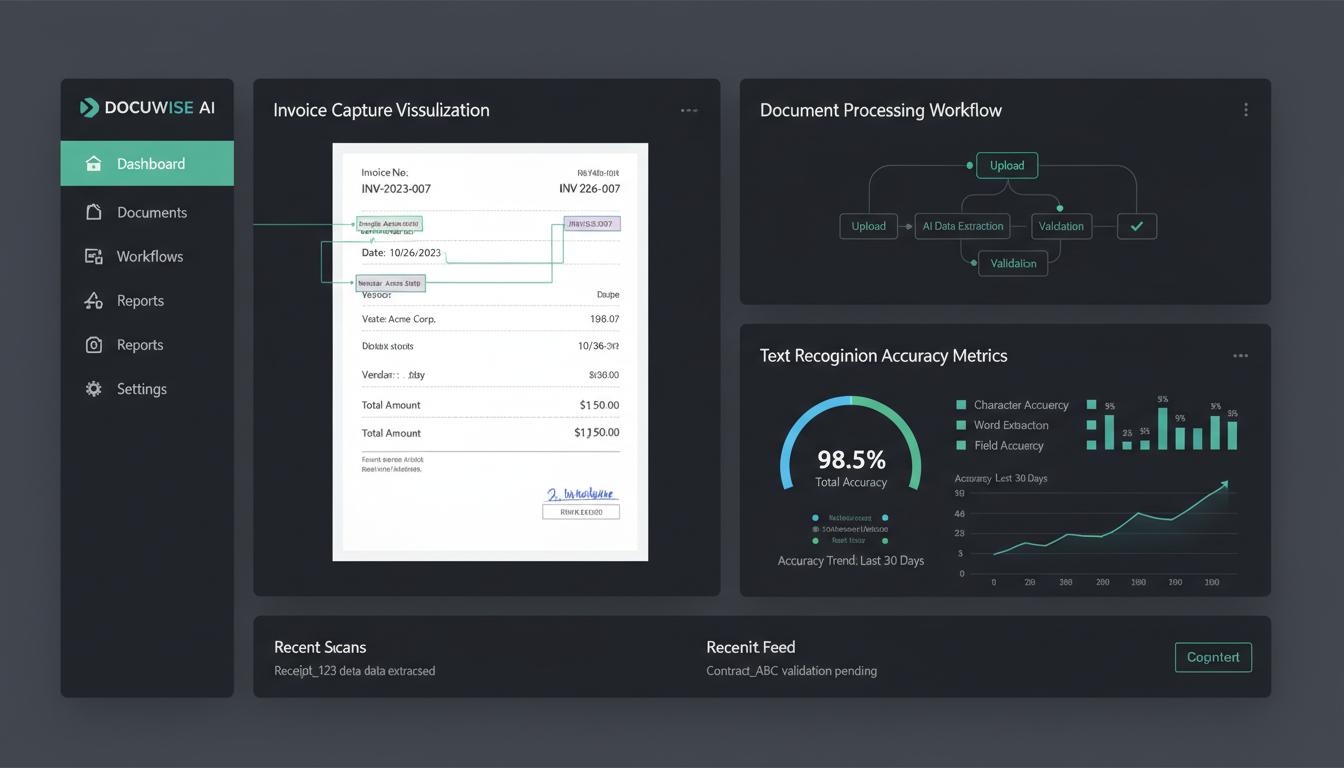
Accuracy Metrics & Benchmarks
Character-level accuracy should exceed 99.5% for printed text. Field-level accuracy should exceed 98% for key data elements. Document-level accuracy (all fields correct) typically ranges 85-95%. Processing speed averages 1-5 seconds per page depending on complexity. Human verification rates should be under 10% for production documents.